2 数据与变量
2.1 2.1 数据来源与样本筛选
2.1.1 2.1.1 数据来源
研究数据来自 CSMAR(China Stock Market & Accounting Research)数据库,覆盖 2010-2025 年 A 股非金融上市公司的年度财务数据,共涉及 7 个原始数据表:
| 数据表 | CSMAR 模块 | 用途 | 关键字段 |
|---|---|---|---|
balance_sheet.csv |
FS_Combas | Lev, Size, Tang | A001000000(资产), A002000000(负债), A001212000(固定资产) |
income_stmt.csv |
FS_Comins | NPR | B002000000(净利润) |
cashflow.csv |
FS_Comscfi | NDTS | D000103000-D000105000(折旧/摊销) |
ownership.csv |
EN_EquityNatureAll | SOE | EquityNatureID |
industry.csv |
STK_INDUSTRYCLASS | 行业FE | IndustryClassificationID=“P0207” |
st_flag.csv |
TRD_Dalyr | ST/PT 标记 | Trdsta |
m2_monthly.csv |
CME_Mfinamkt1 | 宏观控制 | Ezm0109(M2同比) |
数据处理优化(已修复):原始 ownership 表中
EquityNatureID="2,3"(民营+外资双重持股)等复合分类共 1,279 行被错误剔除。已在code/01_data_prep.doL98-110 改用strpos()模糊匹配:“含 1 → 国企”、“仅含 2 → 民营”,回收 820 个公司-年观测、125 家公司。
2.1.2 2.1.2 样本筛选流程(5 步)
样本筛选严格遵循资本结构文献惯例(参见 output/tables/sample_filter.txt):
| 步骤 | 筛选规则 | 删除观测数 | 剩余观测数 | 剩余公司数 |
|---|---|---|---|---|
| 1 | 初始样本(2010-2025) | — | 62,629 | 5,825 |
| 2 | 剔除金融、保险行业(证监会代码 J) | 1,163 | 61,466 | 5,722 |
| 3 | 剔除曾被 ST/PT 处理的公司 | 12,367 | 49,099 | 4,864 |
| 4 | 剔除资不抵债样本(Lev>1 或 Lev<0) | 29 | 49,070 | 4,863 |
| 5 | 剔除关键变量缺失观测 | 20,805 | 28,265 | 3,724 |
筛选剔除率分析:
- 步骤 3(ST/PT 剔除)最大幅度(-12,367 obs,占初始 19.8%)。剔除原因是 ST/PT 公司面临经营异常或退市风险,资本结构决策受非正常因素干扰,包含会污染识别。
- 步骤 5(缺失值剔除)第二大(-20,805 obs,占 step4 的 42.4%)。详细机制见附录:“仅 ind_code 缺失”占 48.7%(行业分类版本仅采用 P0207 导致 1,103 家公司无匹配),“仅 soe 缺失”占 16.9%(外资和”其他”产权未纳入),“仅 growth 缺失”占 13.6%(公司首年自然无 t-1 资产)。
- 步骤 4 仅删除 29 obs,说明数据已较干净,极端杠杆率(资不抵债)样本在 2010-2025 年的 A 股极少见。
最终样本含 28,265 个公司-年观测、3,724 家公司,其中国企 6,767 obs(23.9%),民企 21,498 obs(76.1%)。
2.2 2.2 变量定义
2.2.1 2.2.1 被解释变量
\[Lev_{it} = \frac{\text{总负债}_{it}}{\text{总资产}_{it}}\]
2.2.2 2.2.2 核心解释变量
\[NPR_{it} = \frac{\text{净利润}_{it}}{\text{总资产}_{it}}\]
NPR 同时承担两层含义:(i)当期盈利能力的直接度量;(ii)按 Myers-Majluf 优序融资逻辑,作为信息不对称程度的反向代理(盈利越高 → 留存越足 → 越少需要外部融资 → 信号问题越小)。
2.2.3 2.2.3 控制变量
| 变量 | 定义 | 预期符号 | 理论依据 |
|---|---|---|---|
| Size | \(\ln(\text{总资产})\) | \(+\) | 大公司更易获债务融资(Frank & Goyal 2009) |
| Tang | 固定资产/总资产 | \(+\) | 抵押品价值(权衡理论) |
| Growth | \((TA_t - TA_{t-1})/TA_{t-1}\) | \(+/-\) | 投资需求 vs 留存增长 |
| NDTS | (折旧+摊销)/总资产 | \(-\) | 非债务税盾替代债务税盾(DeAngelo-Masulis 1980) |
| SOE | 国企=1, 民企=0 | — | 调节变量 |
| m2_growth | M2 同比增长率 | \(+/-\) | 货币环境(仅 M1’ IFE 使用) |
2.2.4 2.2.4 异常值处理
对所有连续变量(Lev, NPR, Tang, Growth, NDTS)按年度进行双侧 1% Winsorize。这种处理方式保留了截面分布的尾部相对位置,但限制了极端值对回归系数的杠杆效应。
2.3 2.3 描述性统计
2.3.1 2.3.1 全样本与分组对比
表 2.2 报告了全样本及国企/民企分组的主要变量描述性统计(与 output/tables/descriptive_all.txt 完全一致):
| 变量 | 全样本均值 | 全样本标准差 | 国企均值 | 国企标准差 | 民企均值 | 民企标准差 |
|---|---|---|---|---|---|---|
| Lev | 0.3806 | 0.1906 | 0.4630 | 0.1953 | 0.3547 | 0.1816 |
| NPR | 0.0380 | 0.0598 | 0.0327 | 0.0471 | 0.0397 | 0.0632 |
| Size | 22.0669 | 1.2138 | 22.8403 | 1.4066 | 21.8234 | 1.0328 |
| Tang | 0.1922 | 0.1388 | 0.2031 | 0.1713 | 0.1887 | 0.1267 |
| Growth | 0.1570 | 0.3322 | 0.1188 | 0.3083 | 0.1690 | 0.3385 |
| NDTS | 0.0229 | 0.0142 | 0.0231 | 0.0158 | 0.0228 | 0.0137 |
2.3.2 2.3.2 关键观察与解读
(1) 杠杆率(Lev):
- 全样本均值 38.06%,处于文献中报告的美国均值(35-40%)相近水平
- 国企均值 46.30% 显著高于民企 35.47%(差距 10.83 个百分点,相当于民企标准差的 60%)
- 这一显著差距支持”国企杠杆率系统性更高”的中国资本市场常识,根源于:① 政府隐性担保 → 银行倾向贷款给国企;② 国企历史包袱(如老国企);③ 国企承担更多政策性投资任务
(2) 盈利能力(NPR):
- 全样本均值 3.80%(净利润率 ≈ 总资产收益率 ROA)
- 国企(3.27%)反而低于民企(3.97%)——传统印象中”国企垄断高利润”在这个样本中并不成立
- 民企的 NPR 标准差(0.0632)大于国企(0.0471),说明民企盈利波动更大,更容易出现极端盈利或亏损
(3) 规模(Size):
- 国企平均规模 22.84 ≈ 总资产 8.3 亿元,民企 21.82 ≈ 总资产 3.0 亿元
- 国企总资产约为民企的 2.77 倍(exp(1.0169) = 2.77)
- 与 t 检验结果一致(参见
output/tables/ttest_soe.txt,t=-64.4)
(4) 有形资产(Tang):
- 全样本均值 19.22%,国企略高于民企(差距 1.43 个百分点,t=-7.42**)
- 国企的 Tang 标准差(0.171)大于民企(0.127),反映国企行业分布更广(重资产国企如电力、钢铁的 Tang 极高,金融-类似的国企虽然已被剔除,但仍残存高资本密度公司)
(5) 成长率(Growth):
- 全样本均值 15.70%,国企(11.88%)低于民企(16.90%)(t=10.86***)
- 民企扩张速度显著更快,与”民企更具市场活力”的常识一致
- 但成长率波动也更大(民企 SD=0.339 vs 国企 SD=0.308)
(6) 非债务税盾(NDTS):
- 全样本均值 2.29%,国企-民企差异不显著(t=-1.38, p=0.169)——这是唯一一个组间差异不显著的变量
- 说明折旧政策在两组中相对一致,主要差异来自资产结构而非折旧政策
2.3.3 2.3.3 国企-民企均值差异的正式检验
output/tables/ttest_soe.txt 给出 6 个变量的两样本 t 检验结果:
| 变量 | 国企均值 | 民企均值 | 差异 | t 值 | p 值 | 显著性 |
|---|---|---|---|---|---|---|
| Lev | 0.4630 | 0.3547 | +0.1083 | -42.00 | 0.0000 | *** |
| NPR | 0.0327 | 0.0397 | -0.0070 | 8.42 | 0.0000 | *** |
| Size | 22.8403 | 21.8234 | +1.0169 | -64.36 | 0.0000 | *** |
| Tang | 0.2031 | 0.1887 | +0.0143 | -7.42 | 0.0000 | *** |
| Growth | 0.1188 | 0.1690 | -0.0502 | 10.86 | 0.0000 | *** |
| NDTS | 0.0231 | 0.0228 | +0.0003 | -1.38 | 0.1690 | ns |
解读:除 NDTS 外,所有变量在两组间均差异显著(多数 1% 水平)。这一异质性为后续 M2/M3 分组与交互回归奠定了实证基础。
2.4 2.4 相关系数矩阵
output/tables/correlation_matrix.txt 给出全样本 Pearson 相关系数:
| 变量 | Lev | NPR | Size | Tang | Growth | NDTS | SOE |
|---|---|---|---|---|---|---|---|
| Lev | 1 | ||||||
| NPR | -0.306*** | 1 | |||||
| Size | 0.500*** | -0.003 | 1 | ||||
| Tang | 0.055*** | -0.028*** | 0.048*** | 1 | |||
| Growth | 0.030*** | 0.238*** | 0.032*** | -0.078*** | 1 | ||
| NDTS | 0.053*** | -0.109*** | 0.038*** | 0.707*** | -0.141*** | 1 | |
| SOE | 0.242*** | -0.050*** | 0.358*** | 0.044*** | -0.065*** | 0.008 | 1 |
关键观察:
NPR-Lev 显著负相关(\(r = -0.306^{***}\)):与优序融资理论方向一致,但跨公司维度的相关性弱于 TWFE 估计的内部时变相关性(\(\beta_{TWFE} = -0.544\)),说明公司层面异质性掩盖了部分负相关。
Tang-NDTS 高度共线(\(r = 0.707^{***}\)):折旧主要发生在固定资产,因此两个变量本质相似。VIF 检验未显示严重多重共线性(VIF<5),但解释 NDTS 不显著时需要考虑这一点。
Size-Lev 强正相关(\(r = 0.500^{***}\)):跨公司层面”大公司高杠杆”的特征明显,但 TWFE 系数仅 0.073,说明这一相关主要来自跨公司差异(如 SOE-Size 的 0.358 高相关引出”国企=大公司=高杠杆”链条)。
NPR-Size 几乎无关(\(r = -0.003\)):盈利能力与公司规模无系统性关系,缓解了”小公司高 NPR”或反向的混淆担忧。
NPR-Growth 正相关(\(r = 0.238^{***}\)):盈利改善常伴随资产扩张,是一种”健康成长”模式。
最大相关系数为 Tang-NDTS 的 0.707,未超过 0.8 的高度共线性阈值,回归模型整体设定可接受。
2.5 2.5 图1-图3:基础图形
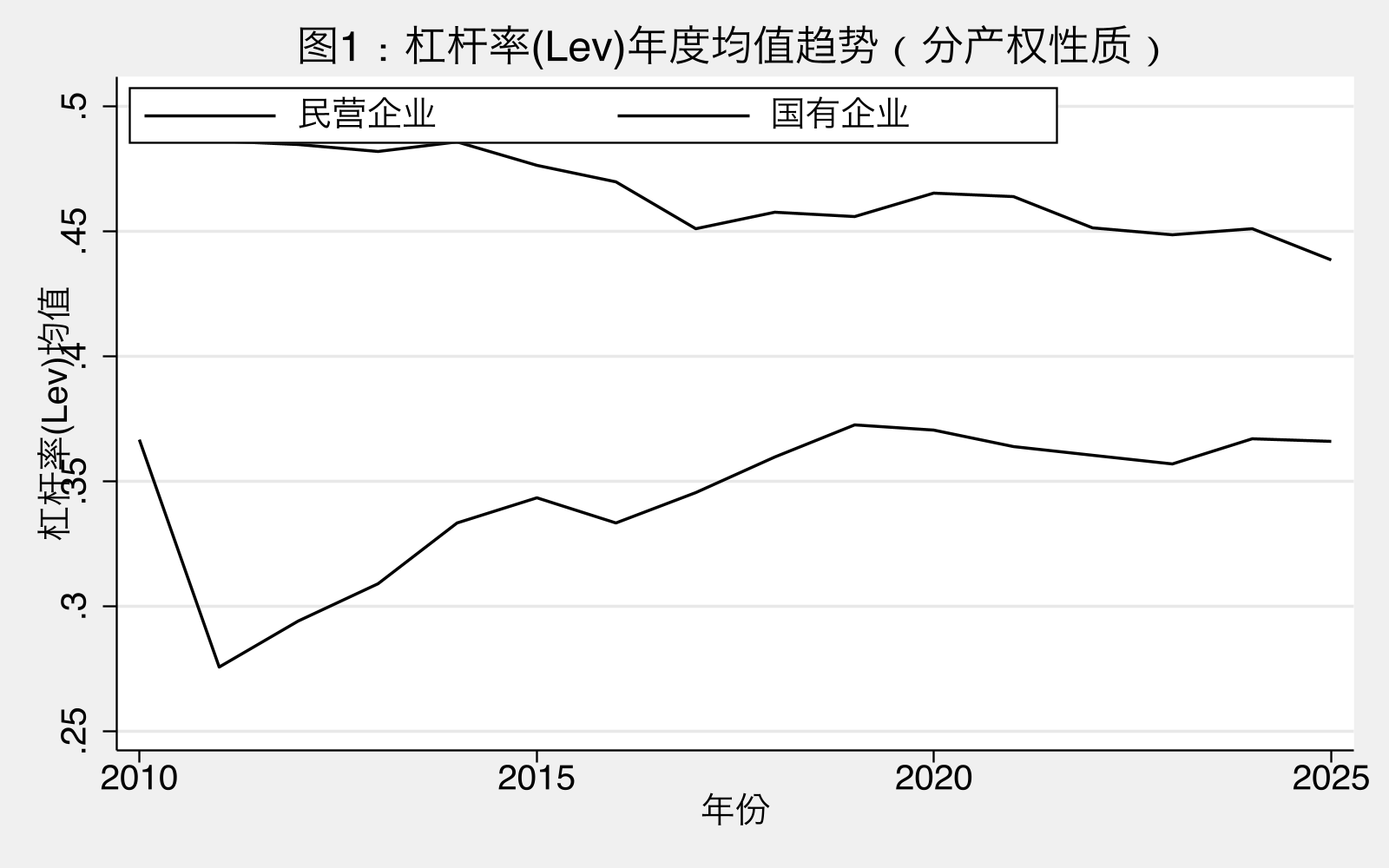
图1解读:样本期内国企杠杆率(红线)始终高于民企(蓝线)。两条曲线呈现:
- 2010-2014:国企-民企杠杆率差距相对稳定(约 8-10 pp)
- 2015-2018:差距收窄(供给侧改革下国企”被动去杠杆”)
- 2019-2025:国企杠杆回升,差距扩大至 11-12 pp
这一时序模式与 M4 的时变系数 U 形演化(参见 4.3 节)相互呼应。
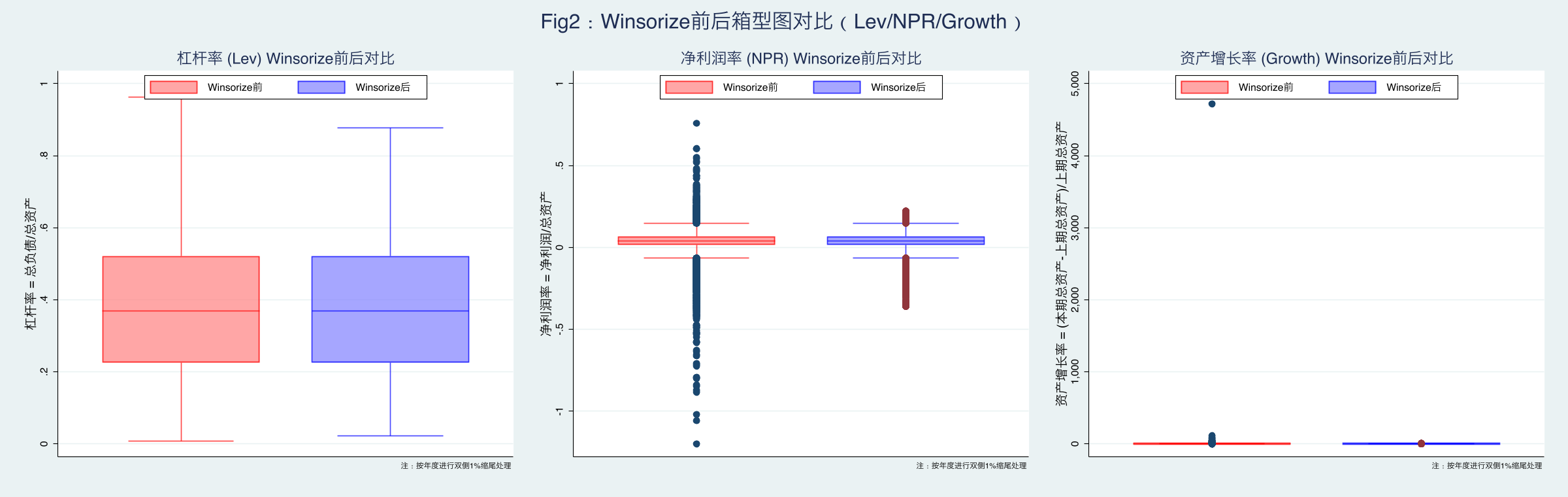
图2解读:缩尾后极端值明显收敛,但中位数位置变化不大,说明 Winsorize 主要压缩尾部而非改变中心趋势。这种处理方式保护了估计免受极端观察值(如某些公司在 IPO 当年 Growth 达数倍)的影响。
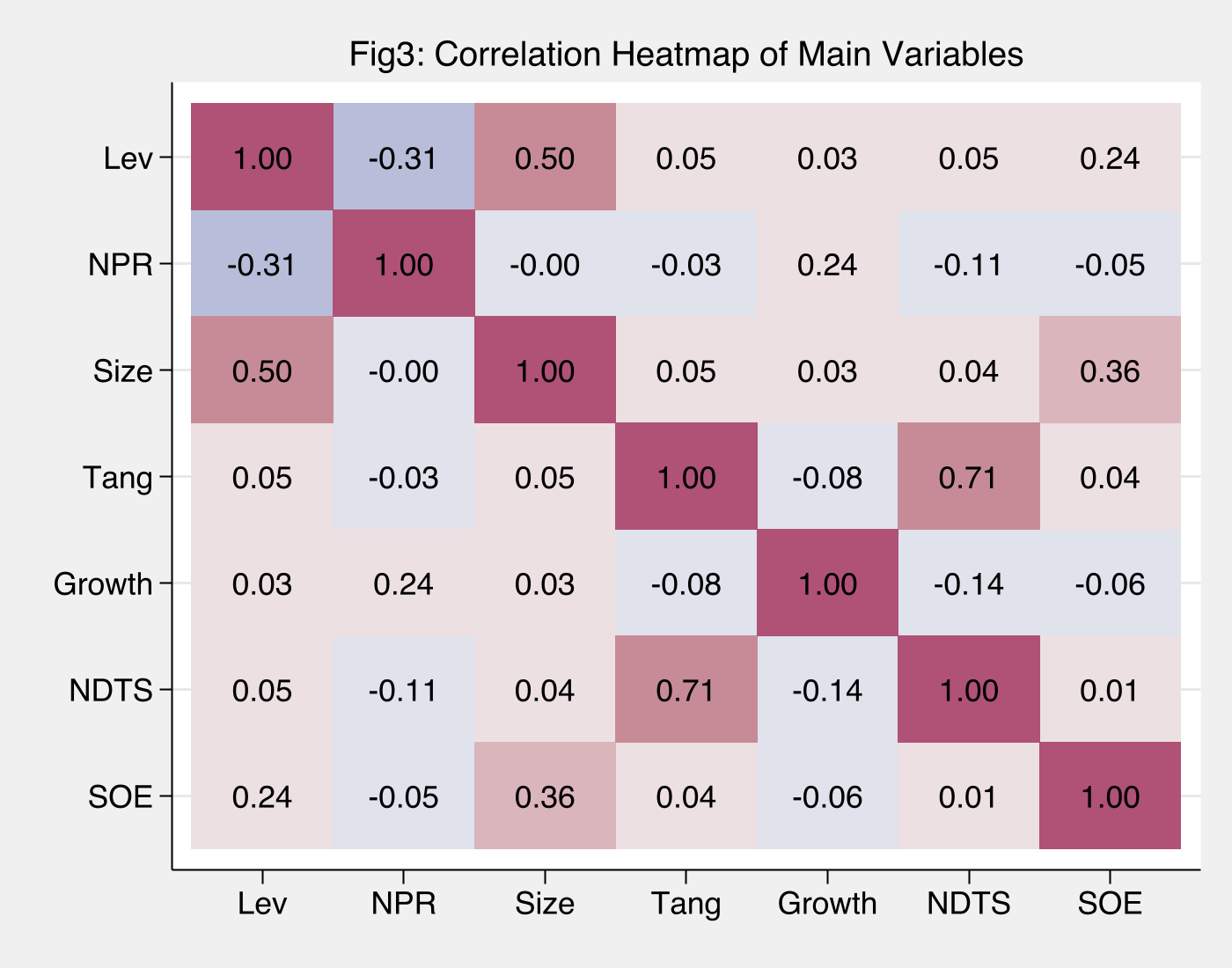
图3解读:热力图直观展现了 2.4 节相关系数矩阵中的关键模式:
- NPR-Lev 的红色(负相关)格子
- Size-Lev、SOE-Size 的蓝色(正相关)链条
- Tang-NDTS 的深蓝色高相关块
为后续回归中的负系数提供直观先验。
2.6 2.6 图8-图9:补充趋势与分布
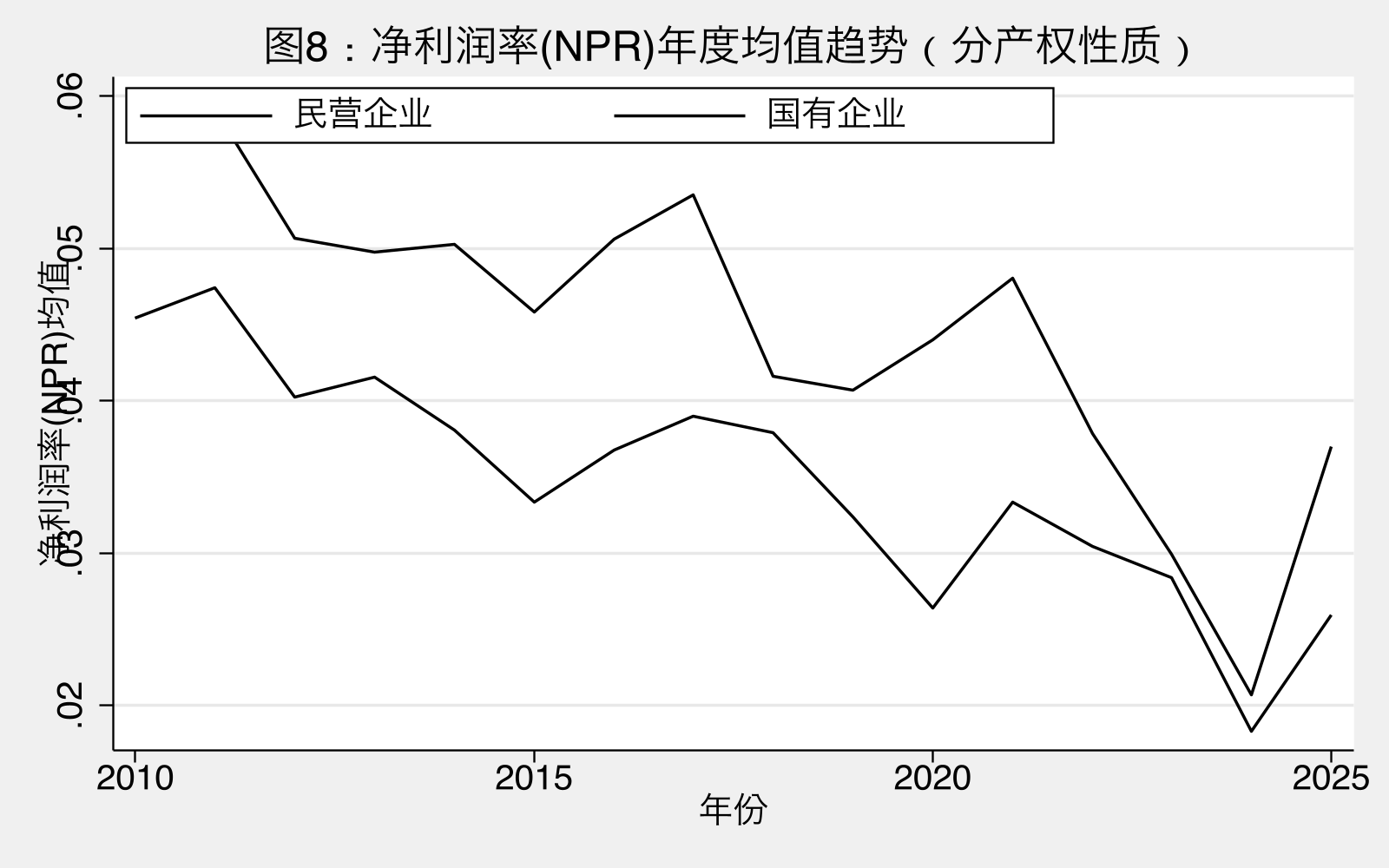
图8解读:民企 NPR 波动幅度大于国企,特别在 2018 年(贸易摩擦)、2020 年(疫情冲击)民企盈利下行更快。这种”民企盈利波动 > 国企盈利波动”的格局与 NPR 标准差对比(民企 0.063 vs 国企 0.047)一致。
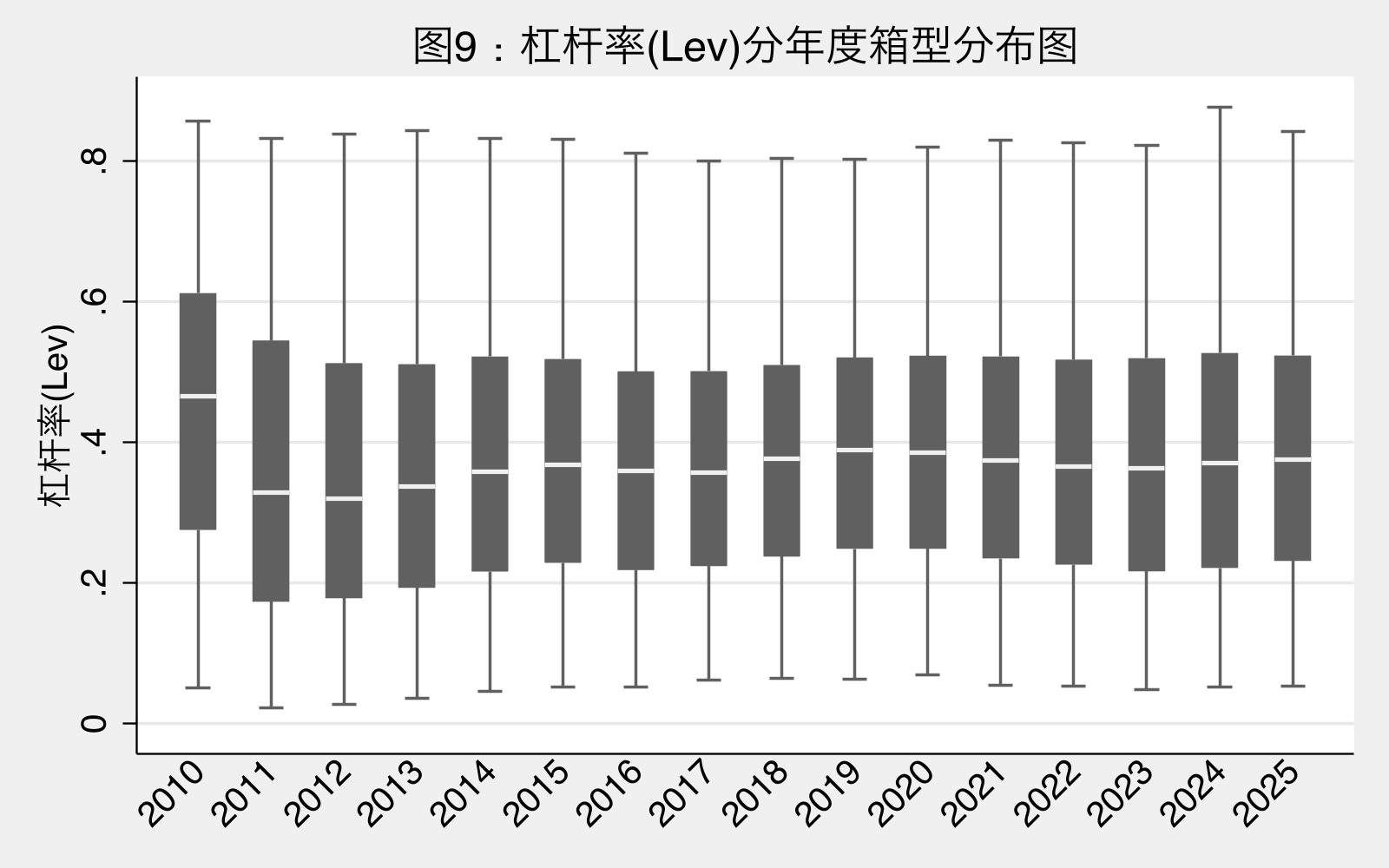
图9解读:杠杆分布中位数总体稳定在 0.35-0.40 之间,年际变化主要来自分布尾部。说明大多数公司的杠杆率结构相对稳定,少数公司的极端调整造成尾部波动。
2.7 2.7 图10-图13:Winsorize 细分对比
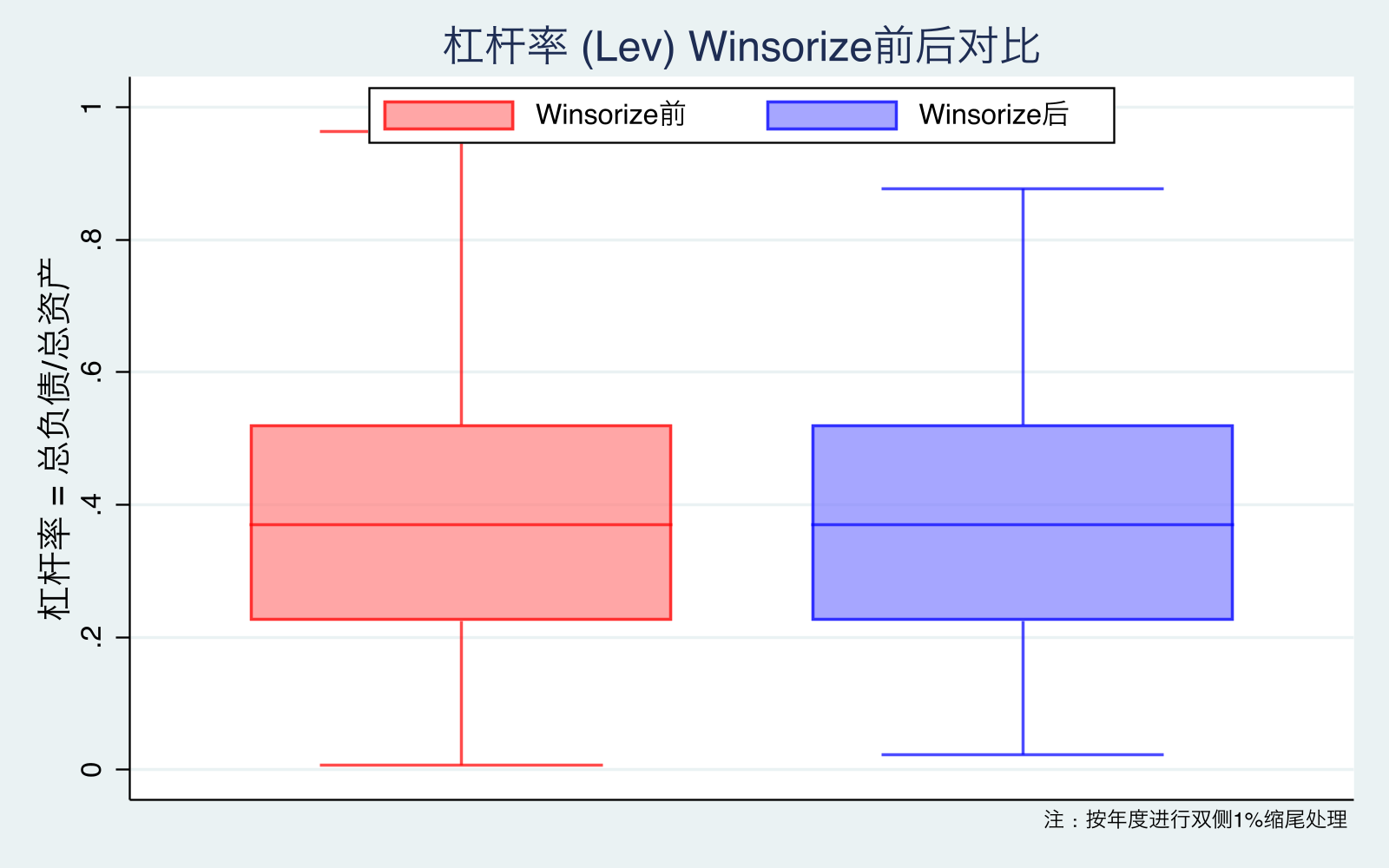
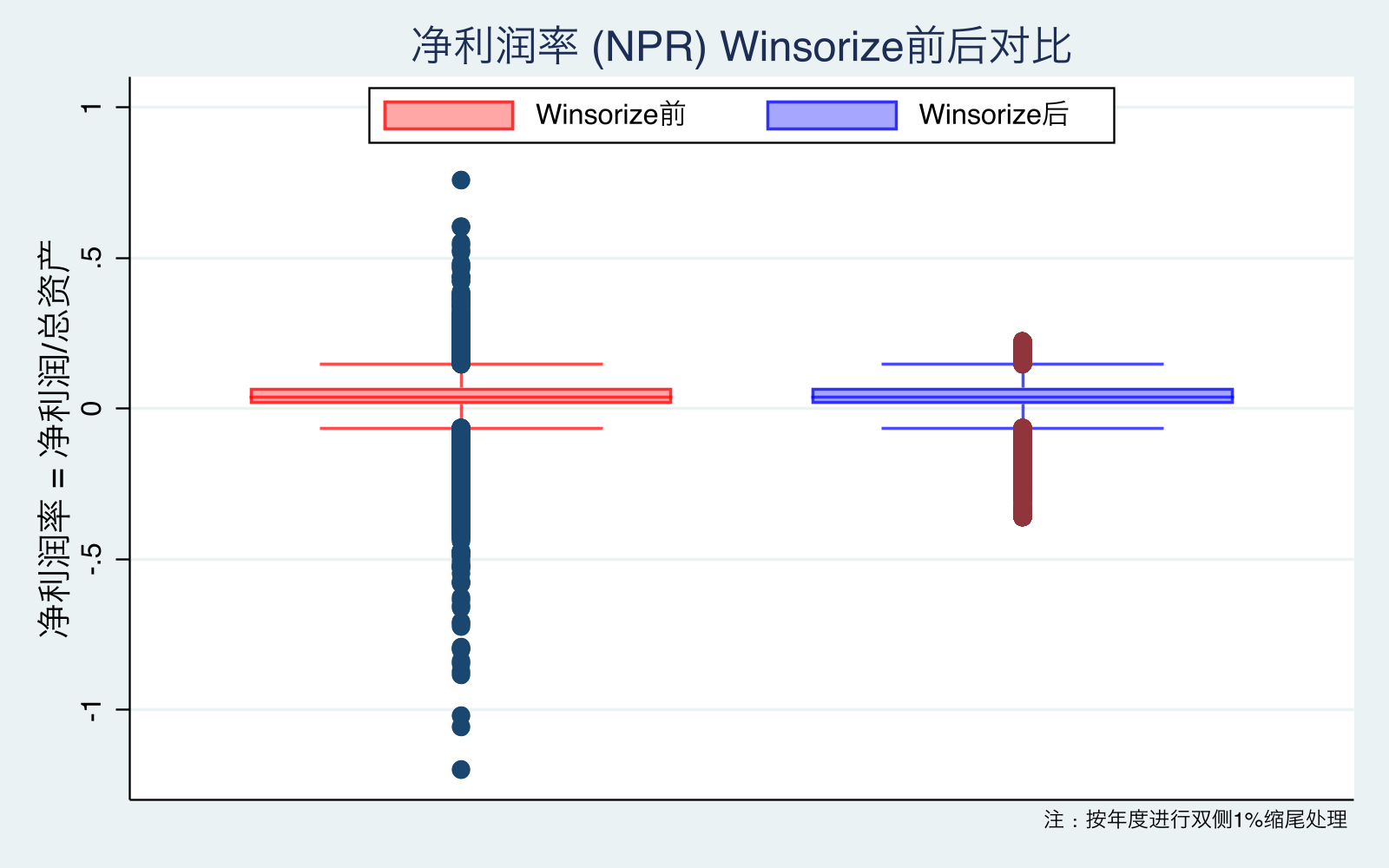
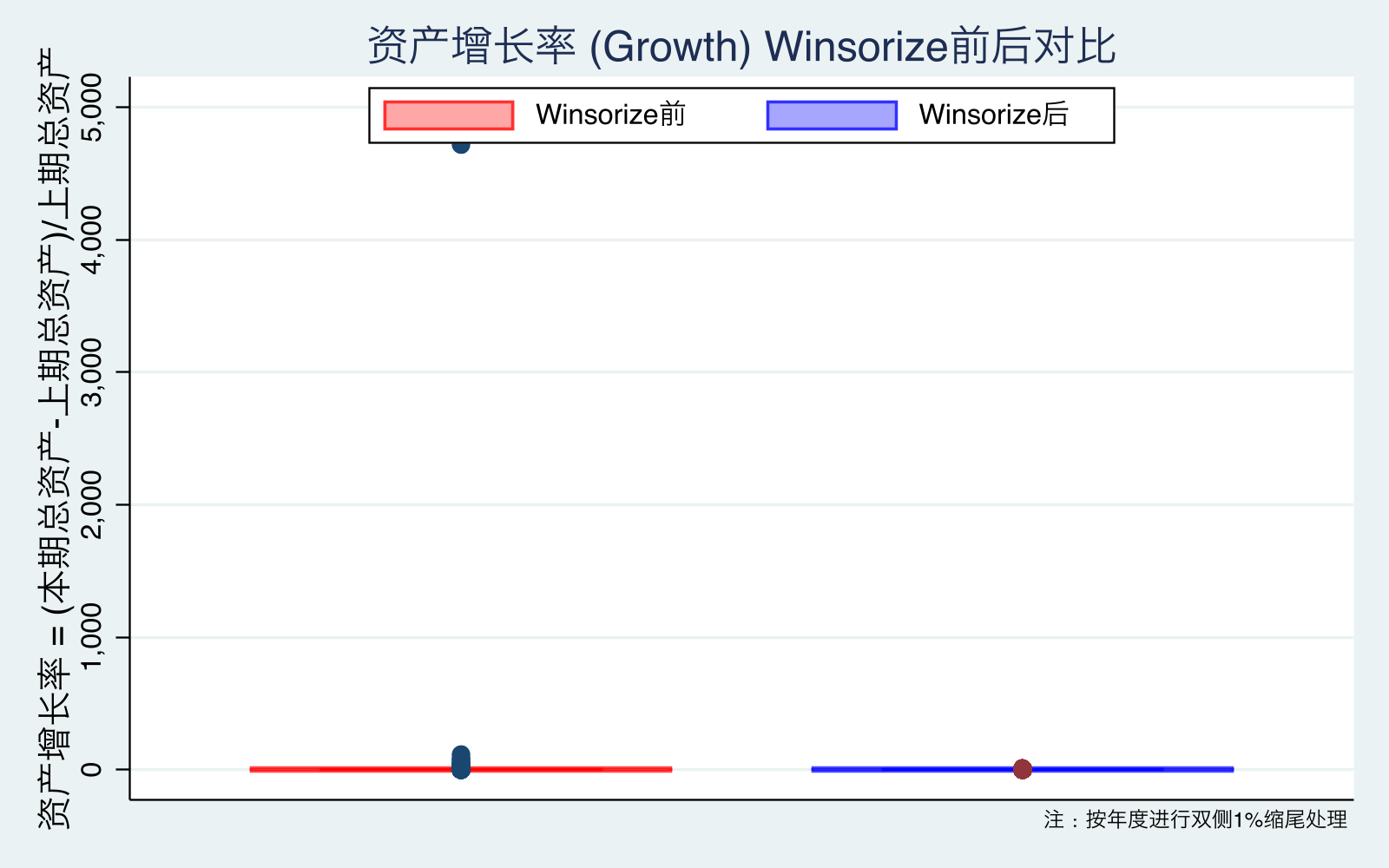

图10-13 解读:
- 图10(Lev):高尾被明显修剪(剔除 Lev>1 后 Winsorize 进一步收敛 99 分位)
- 图11(NPR):负尾和正尾同时收敛——亏损极端值(-1.0 量级)和高利润极端值(+0.5 量级)都被压缩
- 图12(Growth):极端值最多,缩尾前 max>4,缩尾后箱体更可读
- 图13:基于回归匹配样本(剔除步骤 5 后的 28,265 obs),与图10基本一致,验证缩尾效果稳健
总体而言,Winsorize 处理既限制了极端值对回归的杠杆效应,又保留了变量分布的核心特征,为后续回归奠定了干净的数据基础。